上一篇笔记中,聊过了无问芯穹的 MaaS 服务中的“虚拟机”产品。本篇文章来聊聊最近宣传中提到的大手笔免费百亿 Token 用量的“大模型服务平台” 吧。
分享下这个支持异构芯片推理的国产 “Replicate”、模型市场服务使用的经验和小技巧。
写在前面
本篇文章根据我的平台体验展开,如果你更关注平台的产品使用方法,只需要看“获取 API Key” 和 “如何使用模型” 两部分即可。如果你关注平台的产品设计、策略细节,以及国产显卡们的一些情况,那么就跟着文章往下走吧,:D
获取 API Key (Secret Key)
目前所有的 MaaS 平台几乎都支持使用 Open API 调用,并支持使用 Access Token 的方式进行服务鉴权。无问芯穹的产品自然也不例外,访问“密钥管理”页面,就能够看到注册用户后,系统自动创建的 API Key 啦。
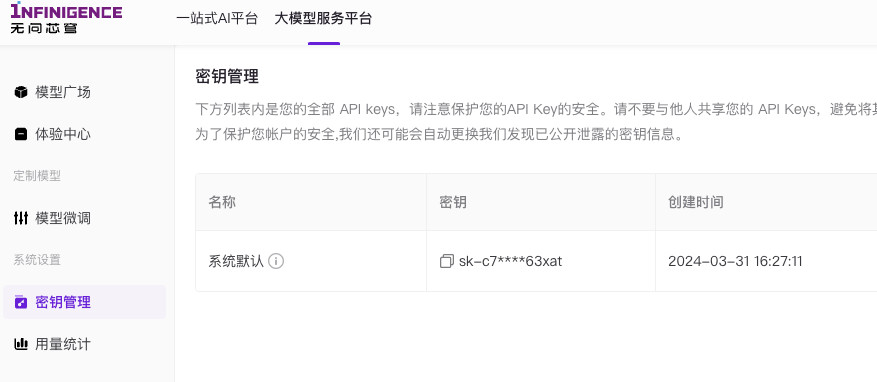
看得出平台想要兼容 OpenAI ,甚至连 Token 的前缀(sk-)都保持了一致,这样在一些开源软件中,是可以符合老版本 OpenAI SDK 或者兼容的 SDK 的验证规则的。(当然,Token 什么的,没有那么重要,因为后面相关的内容里,我会介绍用黑科技来折腾一些非常有趣的实践)
点击界面中相对比较明显的 “复制图标”,在弹窗里输入注册账号关联的手机验证码,验证完毕,就能够得到模型调用 API Key 啦,格式和长度类似下面这样:
sk-soulteary1234567
调用模型的时候,把 “SK” 带上就行啦。以调用千问为例:
curl https://cloud.infini-ai.com/maas/qwen1.5-14b-chat/nvidia/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "qwen1.5-14b-chat",
"messages": [
{ "role": "user", "content": "你是谁?" }
]
}'
平台接口隐藏调用方法
其实,平台的模型接口目前还有一个隐藏的调用方法。在控制台里,官方调用接口并没有发送包含 Authorization: Bearer $API_KEY 的请求头,而是使用了更简单的方法,在请求头里带上当前用户的 UUID,比如:
INFINI_USERINFO_V1=10241024-1024-1024-1024-10241024102410241024
至于用那种,看自己喜好来吧。
获取 API Key (Secret Token) 的改进方案
这里额外提一个有趣的细节,关于用户页面获取 API Key。
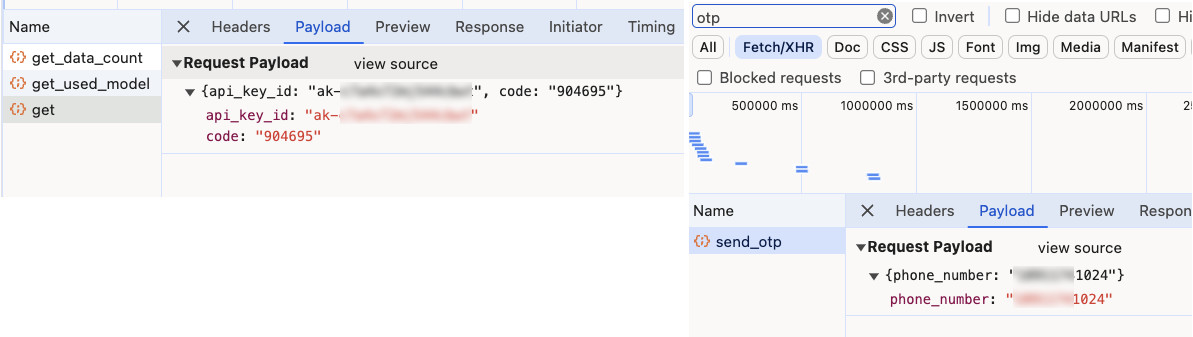
获取 API Key 分为了两步,向用户绑定手机发送 OTP Code(验证码),然后带着用户的 AK (页面中不显示)和第一步得到的验证码去和后端换 Secret Token。
首先是,获取 OTP Code 的时候,是否可以不传递手机号码,而是通过 UUID 来获取,虽然已经使用了 HTTPS ,但是保不齐用户环境单靠 SSL 是无法保障安全的,平台未来如果接入支付能力,调用模型总归是花钱的嘛,一点改进,换来更大可靠,应该是划算的。
其次是,目前页面中的 SK 是部分打码展示的,需要根据 AK 去换取,但是换取过程中,因为手机 OTP 的存在,应该做不到自动化换取。希望后面可以参考 OAuth2 流程,加上 Token 刷新机制,以及监控报警(用量激增、陌生 IP 调用等等)。
最后是,目前在页面中没有找到创建 Token 的地方,如果能够让用户创建,以及设置 Token 额度,如果用在生产环境,就可以非常靠谱了。
当前资源使用限额
相比较“虚拟机”产品公测期间默认的 1 小时测试时间,模型推理公测就非常大方了。这里,官方文档其实提供了一个表格,不过可能开发者之外的用户不会特别有感触:

既然我说他们描述的不够清楚,那么我就来简单解读下数据吧。目前,官方限制每分钟最多请求 12 次,每天最多请求 3000 次(折合每小时不超过 125 次)。其中每分钟允许用户提交 12M Token。满打满算,一天最多能够请求 30 亿(3B)的 Token 数。
3B 是什么概念呢,大概是把哈利波特全集加起来,反复读 3000 遍以上。
所以,如果你想最大化的在测试阶段使用模型资源的话,推荐尽量选择平台目前支持较长文本(32K)的通义千问系列模型或者扩了 32K 上下文的 GLM 模型。其余模型支持长度普遍在 4k~8k。
如果你好奇这个计算是如何实现的,我建议你阅读之前的文章《中文版大模型 Token 成本计算器》,里面提到到各种模型的 Token 计算逻辑。虽然不同的模型有不同的计算(计费)方式,但常见的终归是这么四种:gpt2、p50k_base、p50k_edit、r50k_base、cl100k_base。
当前支持的模型和“显卡们”
在使用平台前,了解平台支持把哪些模型跑在哪些显卡上,对于了解平台核心能力(MxN)和后续使用或许会有好处。
平台支持运行的模型
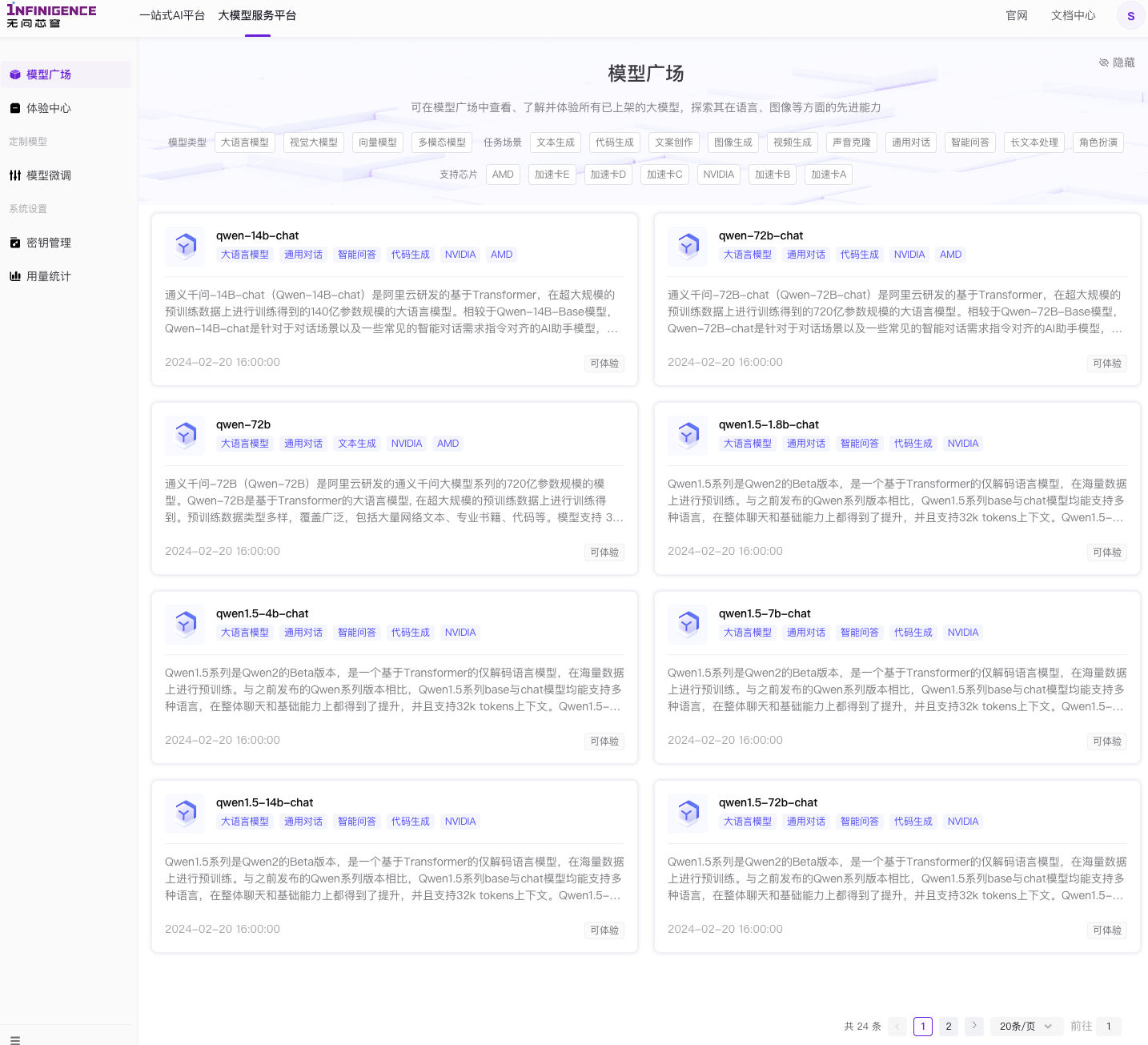
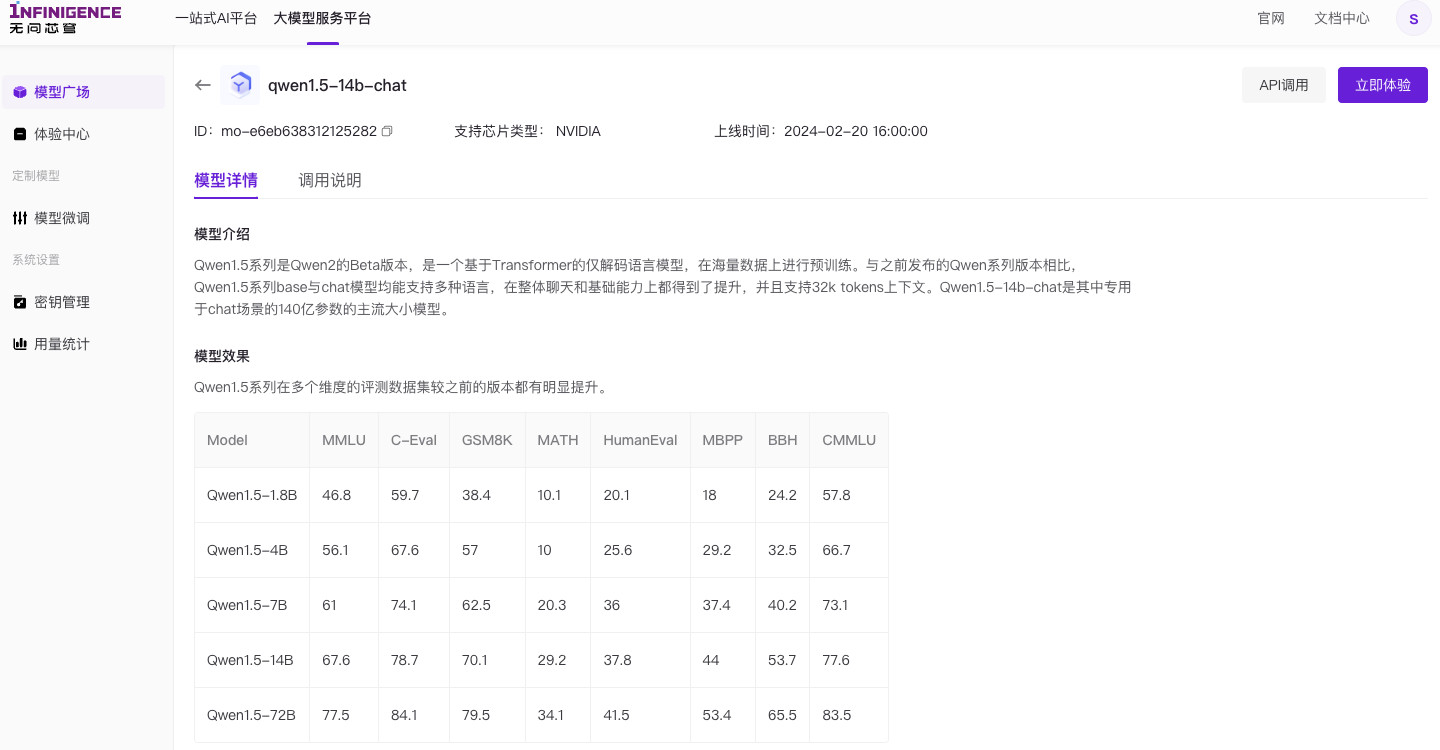
我们在网站的“模型广场”,能够看到目前已经适配和支持的全部 24 款模型。官方分了两批更新,分别是过年后第二天(2 月 20 日,周二)和上周三月底的周二。个人推测无问芯穹的发布火车的日期就是每周二,哈哈。
这两次更新分别包含:llama2、千问、infini-megrez、baichuan2;在 3 月底,适配上线的则是清华系的 ChatGLM 2 和 ChatGLM 3 的 6 个模型。
平台支持推理的显卡
或许,官方是考虑到合作伙伴的“面子问题”,也或许是为了避免用户测试过程中反馈显卡负面舆情给合作伙伴带来舆论困扰。平台页面上目前除了 Nvidia 、AMD 之外的“显卡”(加速卡)都进行了匿名处理,这些加速卡化名为 “加速卡 A~E”。
不过,因为平台设计的 OpenAPI 调用规范中,请求显卡资源,需要带上显卡 Vendor 信息,所以实际上我们还是能够从默认列表接口中获取所有的“显卡基础信息”(整理方案见章节“其他:整理平台模型列表”)。
毕竟,作为用户和潜在的显卡购买者、平台服务消费用户,在使用模型和“显卡”的时候,知道的信息更多些,总归是好的嘛。
下面是打乱了顺序的“加速卡”名称和它们适配了的模型:
- Nvidia,官网:英伟达,所有模型都可用。
- AMD,官网:超微半导体,适配了十二款模型。
- iluvatar,官网:天树智芯,适配了
llama-2-7b-chat和qwen-7b-chat。 - metax,官网:沐曦,只适配了
llama-2-7b-chat。 - moorethreads,官网:摩尔线程,只适配了
llama-2-7b-chat。 - biren,官网:壁仞科技,只适配了
llama-2-7b-chat。 - enflame,官网:燧原科技,适配了
chatglm2-6b和chatglm2-6b-32k。
在整理出的数据列表中,暂时没有发现包含“华为昇腾系列(HUAWEI Ascend)”,个人认为,在国内信创大趋势下,应该很快能够在平台上见到相关芯片吧。
当然,显卡信息除了厂商之外,还有一些比较重要的参数目前是“隐藏信息”:
- 显卡型号、推理使用数量
- 网络相关信息,组网通信方案和实际带宽使用情况
- 主机基础配置,推理服务实际使用资源情况,相关环境是否虚拟化负载一致
- 硬件驱动,相关生态依赖版本是否一致或者性能是否接近
因为上面这些信息都还是黑盒,所以,目前测试所呈现的性能,目前应该是具备一定的参考价值,但或许不完全能作为精准数据来做严格的 benchmark 比较。期待平台将相关数据完全披露,并发起或者结合一些简单好用的“评测规则”,将其固定为标准推广,国内太缺中立身份下场带着“尺子”的创业公司了。
或许只有这样,当大家需要去了解和度量加速卡的性能时,能够更好地做出决策,比如,是不是能够在生产场景下多挺几回国产。另外一方面,也能够鞭策下这些硬件厂商,更多地走出“仿真环境下”或“交差”场景,更多地走进大家的生产环境。
快速使用模型
在平台上快速上手模型有两个方案,分别是网页端的“游乐场试玩”,和使用 API 进行调用。
如何使用模型:入门篇
想要在无问芯穹上快速体验到模型,最简单的方法就是从上面提到的列表页找到你想要玩的模型,然后进入模型的详情页面,点击右上角清华一贯的过饱和紫色按钮“立即体验”。
点击体验后,我们会来到模型的 “Chat” 聊天页面,在页面左侧,目前支持的是“大语言模型”,所以后续应该会支持“多模态模型”、“文生图、文生视频、文生音乐、图生视频、图生图、声纹识别”等等吧。毕竟推理速度都提升了,只跑文本是不是有点不够意思?GKDGKD~
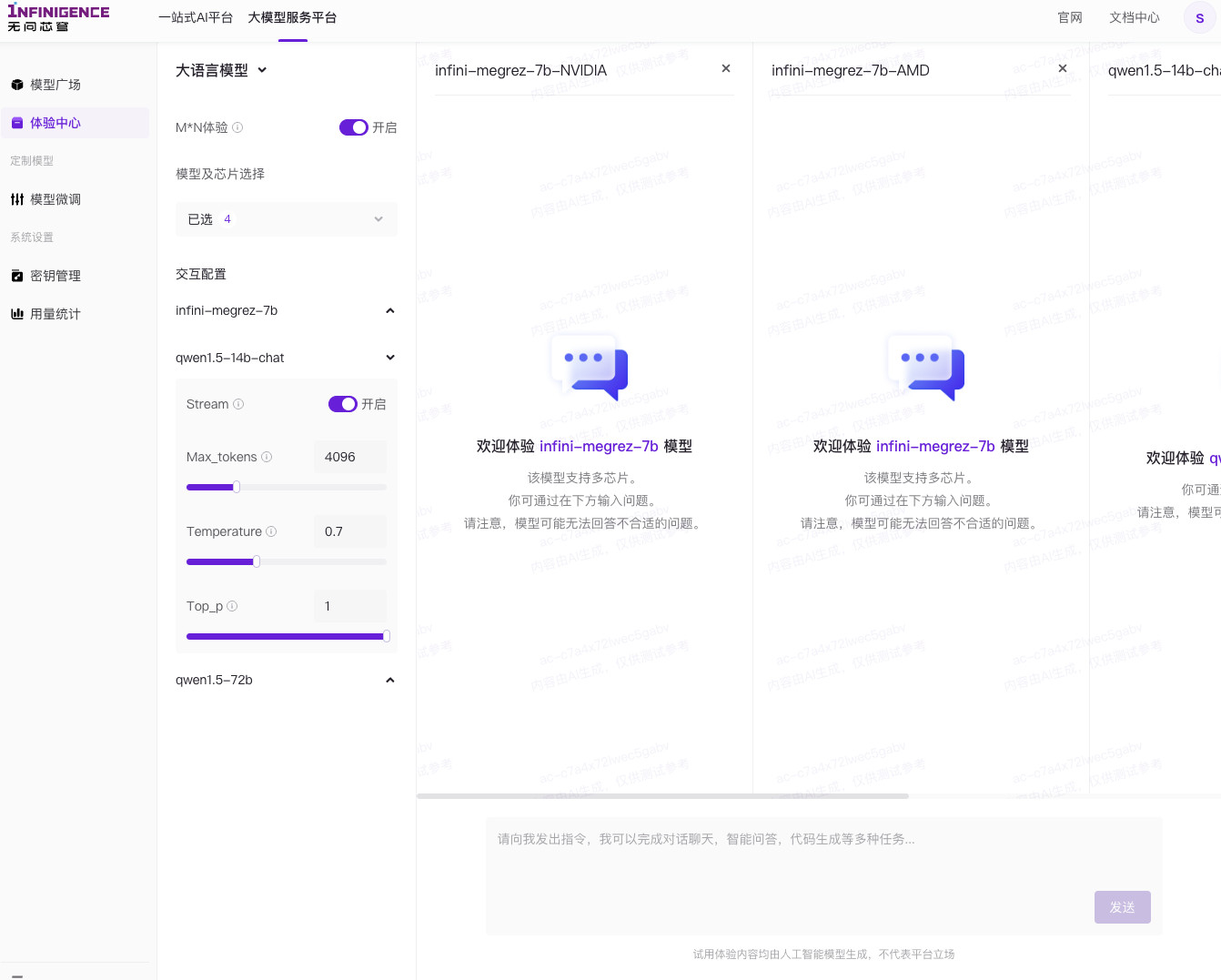
我建议在玩的时候,直接开启“MxN 体验”,让相同模型在不同显卡上做对比,以及不同模型在相同显卡上做对比,是骡子是马,拉出来遛一遛嘛。
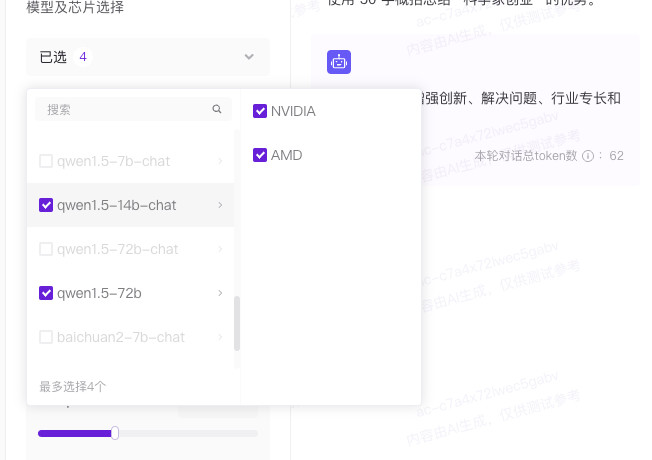
当然,别忘记上文中提到的,目前测试的信息披露还不够完整,非对称信息情况下,评测数据有参考价值,但不能作为准确数值使用,来辅助诸如采购等决策。

选择好你想对比测试的模型,然后在聊天输入框输入内容,发送消息,就能够看到推理飞快的响应结果啦。这里推理速度快慢和平台有关,推理结果和效果不完全和平台相关,毕竟是黑盒模型嘛。如果官方后续能够完整开放模型参数就好啦,比如将 top k、presence_penalty 等等参数也都提供出来,用户对比或者实际在生产中使用,也更靠谱一些。当然,示例中的默认超参数也应该使用官方推荐的数值,模型表现效果也会更好。
如何使用模型:进阶篇
相比较在界面上玩,我们离不开平台的网页产品,使用 API,我们就可以在各种软件中使用平台提供的模型能力啦,比如:langchain、dify、llama-index,或者各种 ChatBot、ChatWeb、Agent 软件里。
调用方法很简单,用 curl 来在 Nvidia 显卡上调用“千问 1.5 14B”模型的话是这样,基本上就是 OpenAI 格式兼容的格式:
curl https://cloud.infini-ai.com/maas/qwen1.5-14b-chat/nvidia/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "qwen1.5-14b-chat",
"messages": [
{ "role": "user", "content": "你是谁?" }
]
}'
当然,想丝滑的接入到各种软件里,不对软件做修改,还需要使用一些小工具,下篇相关的文章里,我会详细展开,这里先不赘述。
如果我们想要在生产中使用,因为调用模型的是有开销的,所以最好是在调用模型之前,先调用另外一个接口,算算这笔帐是否合适,我们对于模型的提交内容(Prompt)是否可以优化优化,以及自己做个计费,避免过度调用产生预期之外的费用。
目前,平台给注册用户免费提供大量 Token(3B +/天),还不用太担心这个事情,不过考虑到真想把生产业务大规模上 MaaS 的同学,还是简单展开下。我们可以调用下面这个接口,来计算要让模型计算的内容的长度。
API: https://cloud.infini-ai.com/maas/infini-megrez-7b/nvidia/token_count
Method: POST
REQUEST:
{"model":"infini-megrez-7b","chip":"nvidia","prompt":"使用 50 字概括总结 “科学家创业” 的优势。"}
RESPONSE:
{"model":"infini-megrez-7b","prompt":"使用 50 字概括总结 “科学家创业” 的优势。","token_count":17}
以及,在请求模型的时候,不同模型的上下文长度是不同的,我们可以通过请求下面这个接口,来获取模型的上下文长度,最大化模型使用效率。
API: https://cloud.infini-ai.com
/maas/{model}/{chiptype}/get_model_details
Method: POST
REQUEST:
{"model": "qwen-7b-chat", "chiptype": "nvidia"}
RESPONSE:
{"model": "string", "context_length": 10241024}
当然,模型上下文一般不会变化,我们可以取固定的配置,或者每天轮训一次平台的接口,把结果缓存下来,让程序使用过程中更加高效。我个人建议官方能够出一个统一的配置,这样开发者可以更简单的获取所有的模型,或者可以根据传入参数来筛选指定“系列”的模型,其实更符合大家使用习惯。
这里官方尚未提供这个服务,所以,我就只好 DIY 一下啦。
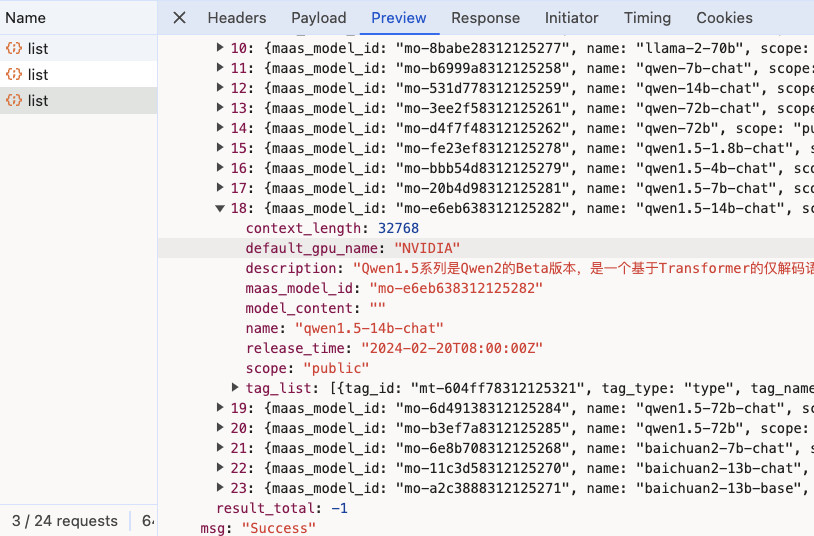
我们从列表页面能够得到官方提供的包含所有模型的列表接口:https://cloud.infini-ai.com/api/maas/user/v2/model/list。这个接口中包含了各个模型的名称,分类信息,支持哪些卡运行和上下文长度。接口返回内容中还有一个 public 字段,推测“企业版”应该也在路上了。

其中有一个字段叫做 “tag_list”,各种显卡支持情况,和模型场景分类的信息就保存在这里。
因为平台产品目测是在快速迭代,文档大概率是跟不上的,所以想要获取最新的平台支持的模型和显卡情况,其实我们可以用几行简单的脚本来搞定。
这里我们偷个懒(下篇再系统化的处理和用这些信息),简单写几行“JavaScript”,来整理下这个接口列表中的数据:
chipTypes=response.data.model_list.map(a=>a.tag_list).flat().filter(c=>c.tag_type=="gpu").map(a=>a.tag_extend_info)
chipTypes.map(chip=>chip.match(`"chipType": "(.+)"}`)[1]).reduce((p, i)=>{
if (!p.includes(i)) {p.push(i)}
return p;
}, [])
我们在浏览器的控制台里,分别执行上面两段代码,就能够得到下面图片中的结果了:平台目前支持的模型都用什么“显卡”,以及到底支持了多少种“显卡”。

(39) ['{"chipType": "nvidia"}', '{"chipType": "amd"}', '{"chipType": "nvidia"}', '{"chipType": "amd"}', '{"chipType": "iluvatar"}', '{"chipType": "metax"}', '{"chipType": "moorethreads"}', '{"chipType": "biren"}', '{"chipType": "nvidia"}', '{"chipType": "amd"}', '{"chipType": "nvidia"}', '{"chipType": "amd"}', '{"chipType": "nvidia"}', '{"chipType": "amd"}', '{"chipType": "nvidia"}', '{"chipType": "enflame"}', '{"chipType": "nvidia"}', '{"chipType": "enflame"}', '{"chipType": "nvidia"}', '{"chipType": "amd"}', '{"chipType": "nvidia"}', '{"chipType": "amd"}', '{"chipType": "nvidia"}', '{"chipType": "amd"}', '{"chipType": "nvidia"}', '{"chipType": "nvidia"}', '{"chipType": "amd"}', '{"chipType": "iluvatar"}', '{"chipType": "nvidia"}', '{"chipType": "amd"}', '{"chipType": "nvidia"}', '{"chipType": "amd"}', '{"chipType": "nvidia"}', '{"chipType": "amd"}', '{"chipType": "nvidia"}', '{"chipType": "nvidia"}', '{"chipType": "nvidia"}', '{"chipType": "nvidia"}', '{"chipType": "nvidia"}']
(7) ['nvidia', 'amd', 'iluvatar', 'metax', 'moorethreads', 'biren', 'enflame']
上文提到的各种模型到底支持多大上下文,我们只需要再稍微整理下就能得到下面的结果:
result: [{infini-megrez-7b 4096 "chipType": "nvidia"} ...]
infini-megrez-7b 4096 "chipType": "nvidia"
infini-megrez-7b 4096 "chipType": "amd"
chatglm2-6b 32768 "chipType": "nvidia"
chatglm2-6b 32768 "chipType": "enflame"
chatglm2-6b-32k 32768 "chipType": "nvidia"
chatglm2-6b-32k 32768 "chipType": "enflame"
chatglm3-6b 8192 "chipType": "nvidia"
chatglm3-6b 8192 "chipType": "amd"
chatglm3-6b-32k 32768 "chipType": "nvidia"
chatglm3-6b-32k 32768 "chipType": "amd"
chatglm3-6b-base 32768 "chipType": "nvidia"
chatglm3-6b-base 32768 "chipType": "amd"
chatglm3 8192 "chipType": "nvidia"
llama-2-7b-chat 4096 "chipType": "nvidia"
llama-2-7b-chat 4096 "chipType": "amd"
llama-2-7b-chat 4096 "chipType": "iluvatar"
llama-2-7b-chat 4096 "chipType": "metax"
llama-2-7b-chat 4096 "chipType": "moorethreads"
llama-2-7b-chat 4096 "chipType": "biren"
llama-2-13b-chat 4096 "chipType": "nvidia"
llama-2-13b-chat 4096 "chipType": "amd"
llama-2-70b-chat 4096 "chipType": "nvidia"
llama-2-70b-chat 4096 "chipType": "amd"
llama-2-70b 4096 "chipType": "nvidia"
llama-2-70b 4096 "chipType": "amd"
qwen-7b-chat 32768 "chipType": "nvidia"
qwen-7b-chat 32768 "chipType": "amd"
qwen-7b-chat 32768 "chipType": "iluvatar"
qwen-14b-chat 8192 "chipType": "nvidia"
qwen-14b-chat 8192 "chipType": "amd"
qwen-72b-chat 32768 "chipType": "nvidia"
qwen-72b-chat 32768 "chipType": "amd"
qwen-72b 32768 "chipType": "nvidia"
qwen-72b 32768 "chipType": "amd"
qwen1.5-1.8b-chat 32768 "chipType": "nvidia"
qwen1.5-4b-chat 32768 "chipType": "nvidia"
qwen1.5-7b-chat 32768 "chipType": "nvidia"
qwen1.5-14b-chat 32768 "chipType": "nvidia"
qwen1.5-72b-chat 32768 "chipType": "nvidia"
qwen1.5-72b 32768 "chipType": "nvidia"
baichuan2-7b-chat 4096 "chipType": "nvidia"
baichuan2-13b-chat 4096 "chipType": "nvidia"
baichuan2-13b-base 4096 "chipType": "nvidia"
为了我们的程序调用方法,也可以直接使用下面的 JSON 格式的配置文件,这样就可以避免总是请求平台,获取模型的基础信息啦,毕竟基础模型的更新频率还是蛮低的:
[{infini-megrez-7b 4096 "chipType": "nvidia"} {infini-megrez-7b 4096 "chipType": "amd"} {chatglm2-6b 32768 "chipType": "nvidia"} {chatglm2-6b 32768 "chipType": "enflame"} {chatglm2-6b-32k 32768 "chipType": "nvidia"} {chatglm2-6b-32k 32768 "chipType": "enflame"} {chatglm3-6b 8192 "chipType": "nvidia"} {chatglm3-6b 8192 "chipType": "amd"} {chatglm3-6b-32k 32768 "chipType": "nvidia"} {chatglm3-6b-32k 32768 "chipType": "amd"} {chatglm3-6b-base 32768 "chipType": "nvidia"} {chatglm3-6b-base 32768 "chipType": "amd"} {chatglm3 8192 "chipType": "nvidia"} {llama-2-7b-chat 4096 "chipType": "nvidia"} {llama-2-7b-chat 4096 "chipType": "amd"} {llama-2-7b-chat 4096 "chipType": "iluvatar"} {llama-2-7b-chat 4096 "chipType": "metax"} {llama-2-7b-chat 4096 "chipType": "moorethreads"} {llama-2-7b-chat 4096 "chipType": "biren"} {llama-2-13b-chat 4096 "chipType": "nvidia"} {llama-2-13b-chat 4096 "chipType": "amd"} {llama-2-70b-chat 4096 "chipType": "nvidia"} {llama-2-70b-chat 4096 "chipType": "amd"} {llama-2-70b 4096 "chipType": "nvidia"} {llama-2-70b 4096 "chipType": "amd"} {qwen-7b-chat 32768 "chipType": "nvidia"} {qwen-7b-chat 32768 "chipType": "amd"} {qwen-7b-chat 32768 "chipType": "iluvatar"} {qwen-14b-chat 8192 "chipType": "nvidia"} {qwen-14b-chat 8192 "chipType": "amd"} {qwen-72b-chat 32768 "chipType": "nvidia"} {qwen-72b-chat 32768 "chipType": "amd"} {qwen-72b 32768 "chipType": "nvidia"} {qwen-72b 32768 "chipType": "amd"} {qwen1.5-1.8b-chat 32768 "chipType": "nvidia"} {qwen1.5-4b-chat 32768 "chipType": "nvidia"} {qwen1.5-7b-chat 32768 "chipType": "nvidia"} {qwen1.5-14b-chat 32768 "chipType": "nvidia"} {qwen1.5-72b-chat 32768 "chipType": "nvidia"} {qwen1.5-72b 32768 "chipType": "nvidia"} {baichuan2-7b-chat 4096 "chipType": "nvidia"} {baichuan2-13b-chat 4096 "chipType": "nvidia"} {baichuan2-13b-base 4096 "chipType": "nvidia"}]
最后
这篇文章就先写到这里啦,无问芯穹的相关产品的基础体验,差不多就先到这里啦。接下来,我应该会在平台的两个产品上折腾一些中文环境下想对少见的有趣内容。比如,如何快速调用模型,如何让模型们打起来,如何在异构服务器上跑一些大家都喜闻乐见的开源模型,以及试试官方的在线 finetune 功能,和模型训练加速能力。
那么,下篇文章再见。
–EOF