本篇文章聊聊正在公开测试的平台,无问芯穹的 MaaS 服务,包含了平台使用体验和一些小技巧。
因为测试给的免费卡时比较少,估计想完成完整测试或许需要一些时间,额外用一些账号进行。就先记录下常规折腾过程吧,让再次“复现”的时候能节约一些时间。
写在前面
上周末去苏州参加 CCF 的会议,回来的路上收到了朋友转发的内容,说有一个新的平台正在开放公测。虽然平台宣传公测的是模型服务(模型 API),但是网站上的“一站式平台”(AI Studio)反而吸引到了我的注意力,如果能在上面直接跑跑最近出的新模型,岂不妙哉。
开始折腾。
第一步:创建账号,登录平台
首先访问 “AI 平台” 的链接,使用手机号注册一个账号。目前没有实名认证,哪怕使用小号注册也问题不大。
注册完毕,登录账号,能够进入 AI 平台的控制台,目前版本的界面比较简单,和绝大多数现有平台类似,不过从数据概览的设计中能够看到是有多人协作(共享资源)的设计的。
平台网站从 IP 推测应该部署在阿里云北京,所以虽然前端没有做优化,访问起来也还蛮快的。
第二步:创建 GPU 主机
虽然目前左侧菜单栏有三种可玩的模式:“开发机(虚拟机)”、“任务(训练任务)”、“推理服务(Docker 推理容器)”,但如果你想稍微深度的使用平台。暂时只有选择第一项。
主要原因是,目前平台有白名单机制,非申请用户是无法直接获取公网 IP 访问能力的。所以,即使你训练模型结束,能够在推理服务使用自己的模型或者直接在推理服务页面,使用平台预先提供的模型,也无法访问和测试模型的具体状况,毕竟同一时间只允许使用一张卡(暂时不能无卡启动容器,来作为测试机)。
既然另外两条路不通,那么我们就选“创建开发机”吧。
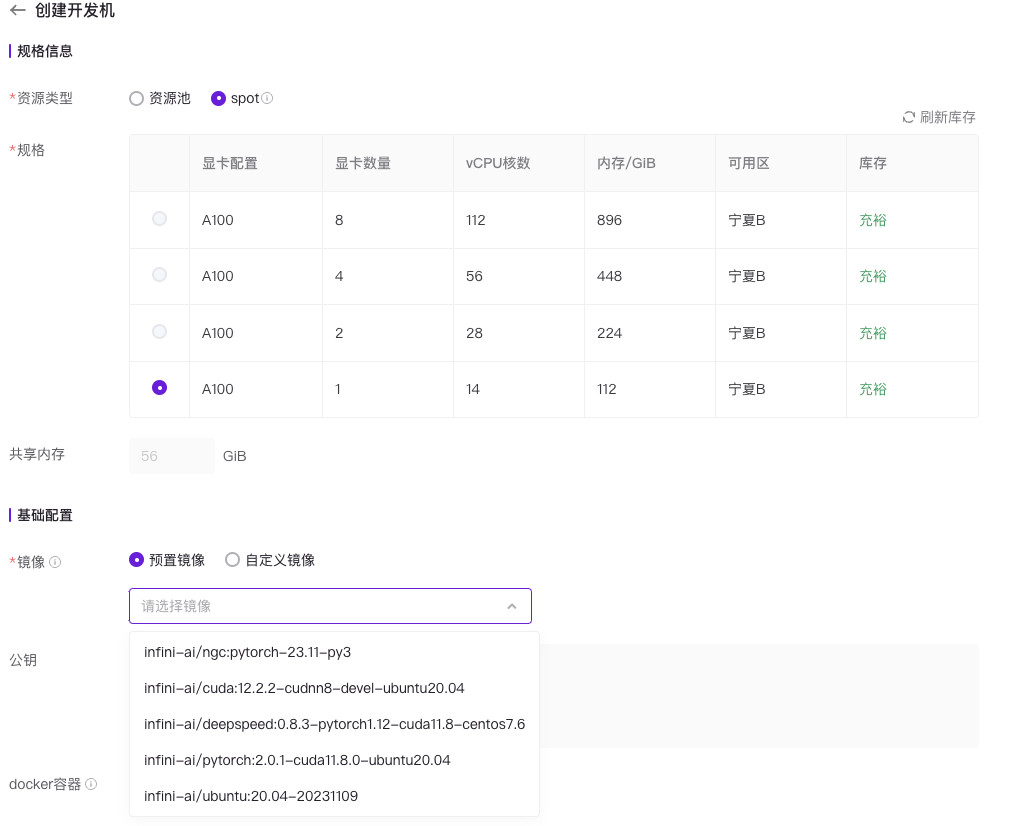
虽然平台列举了 A100 单卡到 8 卡的选项,但是目前其实只有单卡机器能够被选择使用。建议平台隐藏掉其他机型,页面默认勾选可选择机型,操作体验可以更好一些。为了避免环境干扰,我一般会选择基础镜像,比如 Ubuntu。平台自带的 Ubuntu 版本稍低了些,去年3月就停止了一般性更新,如果有可能提供 22.04 LTS 或许会更好一些,用户安装软件也可以省去很多麻烦,持续使用的安全性也更有保障。
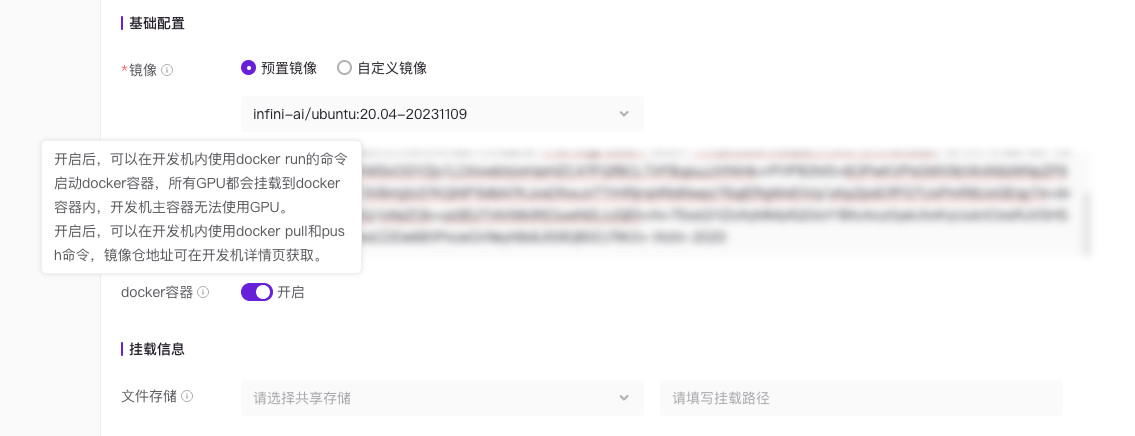
在选择好基础镜像后,添加我们自己的 RSA 密钥,然后给主机起个名字,点击创建主机即可。诸如存储相关的创建主机选项,目前并不支持配置,估计后续官方需要上线一个“存储池”的选项,让大家能够使用文件存储协议来传数据,比如 “FTP / WebDav / S3 / HTTP” 这类常规玩法。
小技巧:突破官方限制,调大共享内存
官方页面中,前端“锁死”了共享内存的容量,默认数值是主机的容量的一半:56GB。但是对于用户来说,只能用一半资源不是太浪费了嘛。
我们通过删除页面输入框元素上的 “Disable” 属性,来把资源设置为 100GB。(给系统留 12G 足够用了)
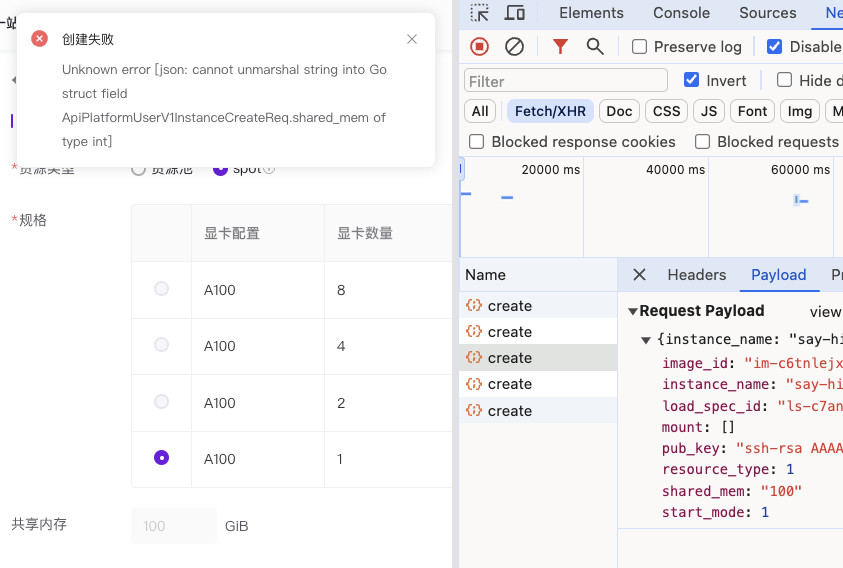
但是,当我们创建的时候,发现系统弹出了后端接口的序列化报错。嗯,无问芯穹的平台是用 Golang 写的啊,具备基础的数值校验,ApiPlatformUserV1InstanceCreateReq.shared_mem 这个字段需要是数值类型,前端默认传递的是字符串。那么,看起来这个接口应该是没有被真正调用过,而这种情况下,一般接口有可能都是可以工作的。
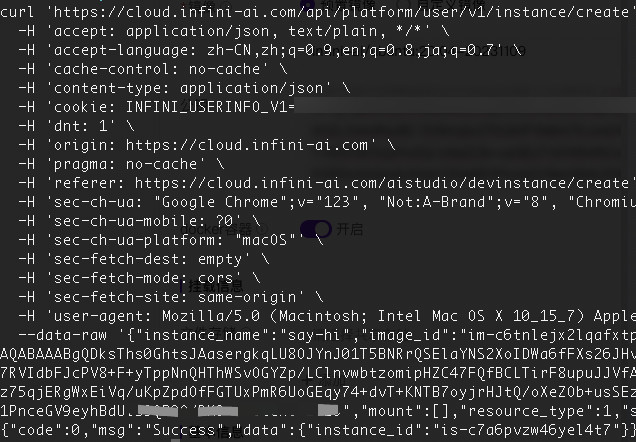
于是,手动创建一个请求,将请求中的字段类型从字符串改成数字,提交请求,接口返回资源创建任务正常执行。

因为我是在凌晨进行测试,资源显然是充足的(目前应该测试用户也不多),所以当我返回开发机列表页面后,稍等十几秒,一个 100GB 共享内存的,能够使用 Docker 的开发机就创建完毕啦。
推测大概率使用了 DinD 来使用 Docker。或许,这个模式下存储共享需要做比较多的约定和 Coding 工作,这也可能也是官方尚未支持存储功能的原因之一。
第三步:使用 SSH 来访问主机
如果你从上面的列表页面直接点击登录,那么你将打开一个基于 xterm.js 构建的前端 SSH 页面。
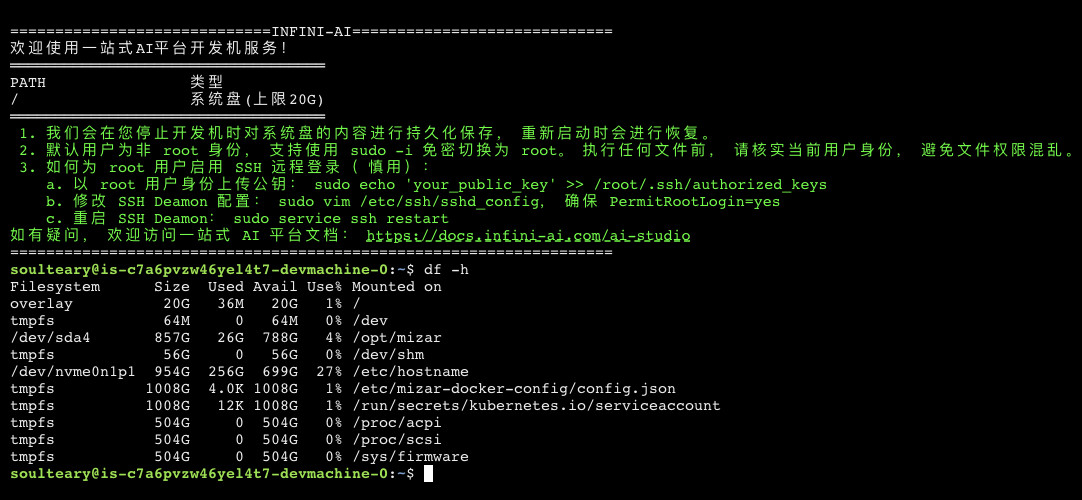
因为平台刚刚建立不久的缘故,支持功能非常少,不能够在页面传递文件,加上默认情况下主机也并未开放常见端口,我们想跑个带有界面的 Chat Bot 或者 Stable Diffusion WebUI 也会比较麻烦。
所以,我个人推荐别点页面的“登录”按钮。点击“三个点”在下拉菜单中选择“详情”,进入示例详细资料页面。

然后在详情页面中,我们能够看到 “SSH 登录方式”。我这里的登录命令是:
ssh -p 40490 soulteary@111.51.90.14
不知道端口是随机的,还是玩梗“404、4090”。从 IP 地址可以看出机器使用的是宁夏银川的移动出口的资源。不知道还有多少人记得这个宁夏算力枢纽节点(全国8个国家算力节点),去年城市提出的口号“打造算力之都做强做大数字经济”,有披露不少数据,等今年年底的时候再看看,到时候对比下。

使用页面提供的命令,我们顺利登录主机。
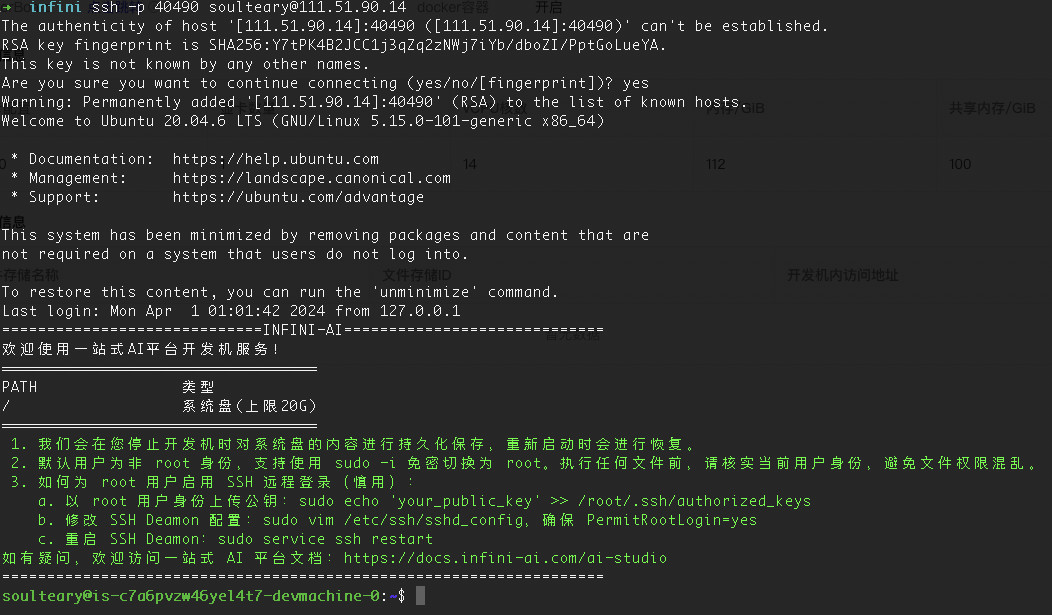
第四步:快速测试平台容器环境
想要快速测试模型容器,最简单的方案就是使用官方已经测试过的模型镜像啦。但是目前平台并没有提供带有模型的镜像列表。没关系,继续自助餐流程。
返回主页,找到“推理服务”,然后“尝试”创建一个推理服务。
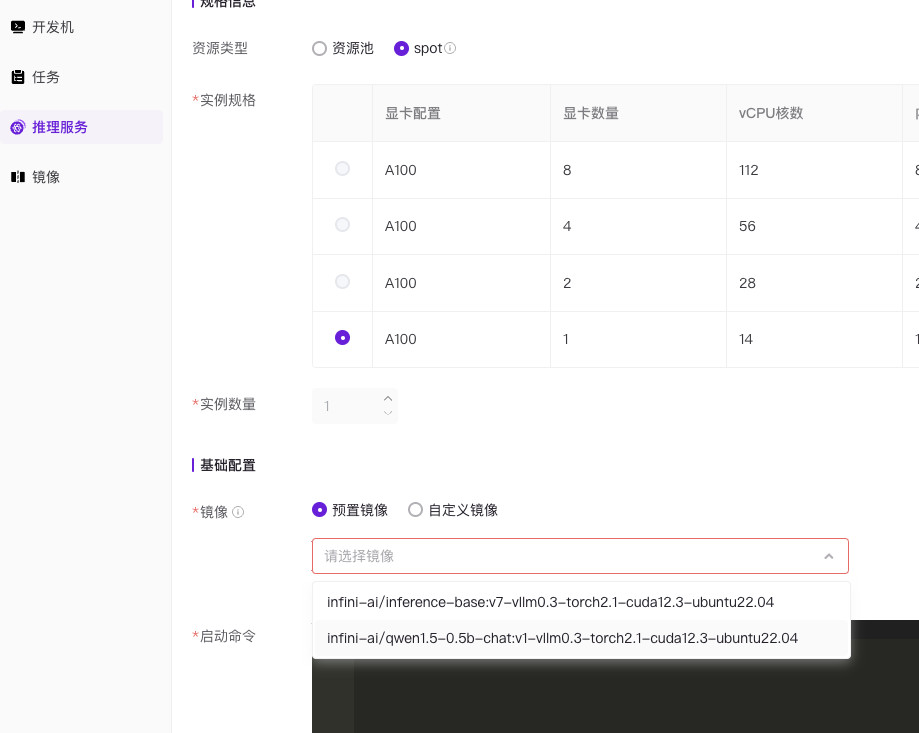
这里我们并不是真的创建,因为一来创建资源的测试额度不足,二来我们只是来推理服务中获取镜像名称的。

当我们选定镜像后(我这里选择的是小巧玲珑的 QWen 0.5B,但其实镜像尺寸有 31G),将鼠标放在镜像下拉列表上,就能够得到完整的镜像地址啦。
得到地址后,自然是在 SSH 中输入下面的命令,把官方预置镜像下载到主机中啦:
docker pull cr.infini-ai.com/infini-ai/qwen1.5-0.5b-chat:v1-vllm0.3-torch2.1-cuda12.3-ubuntu22.04
因为镜像比较大(31G),所以我们下载完毕、容器本地解压缩镜像需要接近 10 分钟。因为我测试了两次,所以白白消耗了测试额度中的 20 分钟。这里如果官方团队能够将常用模型或者环境直接在“开发机”共享存储中提供会方便和节约很多时间。
在运行容器之前,我们需要参考一处文档中的说明,否则想使用容器提供的默认的 entrypoint.sh 程序,启动符合 OpenAI 接口格式的程序是不行的。

文档中的参数(环境变量)配置如下:
export MODEL=qwen1.5-0.5b-chat
export TP=1
export LOG=1
# 模型已经放在 /app/model/${MODEL}
/app/entrypoint.sh
为了让容器正确跑起来,我们需要编写如下命令:
docker run -it -p 8000:8000 -e MODEL=qwen1.5-0.5b-chat -e TP=1 --gpus=all -v=/mnt:/mnt cr.infini-ai.com/infini-ai/qwen1.5-0.5b-chat:v1-vllm0.3-torch2.1-cuda12.3-ubuntu22.04
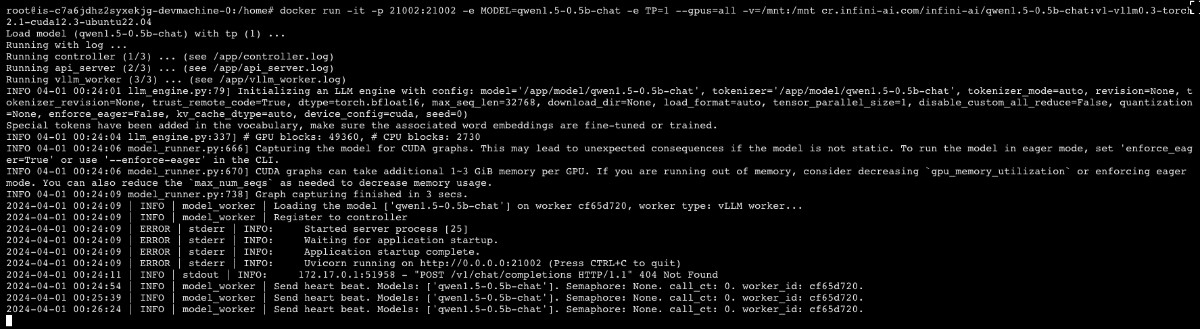
图片中服务启动命令的端口是 21002 (受到容器输出日志误导),实际执行需要使用上面提到的 8000 端口。建议官方把日志显示的真实服务端口 21002 日志注释掉,避免干扰开发者。
启动服务后,我们再打开一个 SSH 终端,然后输出下面的命令,就能够测试容器服务啦。

测试命令代码如下:
curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen1.5-0.5b-chat",
"messages": [
{ "role": "user", "content": "无问芯穹公司介绍" }
]
}'
我连续调用了几次模型,输出结果如下:

调用体感来看,基本是实时输出结果,虽然我使用的模型比较小(0.5B的官方镜像),但是实时出整段结果还是蛮爽的。
其他:碎碎念
第一篇相关的测试就到这里啦,因为当我想继续测试的时候(第二次复现)。平台测试赠送额度使用完毕了,就实际体验来看,应该是新用户每人赠送一小时 A100 卡时(大概 6~8 块钱)。
等有空的时候,再进行其他的测试,比如各种平台的联通性、模型下载和上传速度、最常规的 finetune 时间是否有加速,以及平台目前没有涉及,但是大家都玩的比较熟悉的 Stable Diffusion 相关的跑图和炼丹。
毕竟有了 SSH ,其实我们就可以无障碍访问 Web 服务了嘛。
最后
个人感觉相比较海外学者创业,无问芯穹的环境显然不够有优势。但是依旧希望汪老师带队的,这只擅长硬件能力的,在一种软件局面下显得“相对小众”创业公司能够在中国的 AI 创业史上落下惊鸿一笔。
产品嘛,还在内测,在让子弹飞一飞吧。
–EOF